p53 is a tumor protein associated with the regulation of cell growth. It is frequently found to be mutated or inactivated in 60% of hereditary cancers. In this assignment we'll get some exposure to some of the key bioinformatics tools and databases on the web to explore p53.
Go to the Entrez database browser at the National Center for Biotechnology Information (NCBI). NCBI is one of the institutes of health under NIH. This page will soon become our portal of choice, our default start point for any search and exploration. You may want to bookmark it so that you can go there easily. It should take you to a webpage with the title "Entrez, The Life Sciences Search Engine" at the top of the page. Click on "All Databases" to see all the databases you have access to. Study this page briefly. Click on "GenBank" on the top panel. It should take you to the webpage for GenBank. On the left panel, you will find several links. One of these is a link to "GenBank and RefSeq: a comparison". You will need to read it in order to answer question Q1 below. There is another link to Search GenBank. Click on it. You will search for human protein "p53". Make sure you search in the protein database by clicking on "Protein". On Feb 5, 2008, this gave me 6197 hits.(The same search this week had 8125 hits. Modify your search to look for "p53 human" and you should still get 3614 hits. Now modify your search to look for "p53[Gene Name] AND Human[Organism]". This can be achieved as follows: Delete the phrase "p53 human" you typed earlier for the search, and click on "Advanced Search". Then use the "Search Builder" to type p53 as the "Gene Name". Next type human, click on "Organism", click on "AND", and click on "Add to Search Box". This should enter the required phrase "p53[Gene Name] AND Human[Organism]" for the search. Now click on "Search" to launch the search. You should still get 41 hits. You can change the "Display Settings" to see all 41 hits sorted by, say, "Release Date". We still need to narrow down the search further. So we are going to try a different strategy. Instead of searching in the "Protein" database, let us search in the "Gene" database. Entrez Gene is a searchable database of genes from RefSeq Genomes.
Q1: Define RefSeq in a sentence or two. RefSeq accession numbers can be distinguished from GenBank accessions by their distinct prefix format of 2 characters followed by an underscore character ('_'). All RefSeq nucleotide and protein records start with two specific characters. What are they?
Later you can figure out the RefSeq identifiers for p53 nucleotide and protein sequences. Continuing on our search for p53, the query "p53[Gene Name] AND Human[Organism]" at Entrez Gene. This gives just three hits. The correct one is the gene called "TP53" for "tumor protein p53 (Li-Fraumeni syndrome) [Homo sapiens]". The first hit called "HCP5P3" is not the right one since it is a "PseudoGene". (Find out what that means.) The second one is not the right one either since it has been replaced by the first entry. Click on TP53. It will lead you to a page with enormous amounts of information on TP53. Read the summary information on this gene and make sure you understand it. Now look at the section titled "Genomic context". Look at the genes adjacent to it on the chromosome. Genes can lie on the forward strand or on the reverse strand. You will even find a gene that overlaps with TP53.
Q2: What is its Official Symbol and Full name? What is HGNC (which provides the symbol and name information)? What chromosome is this gene on? What are its alternative names? What strand does p53 lie on? Write down the names of the genes adjacent to it along with the strand that the neighbors are on. Identify the gene that overlaps with TP53 on the genome.
Next look at the section titled "Genomic regions, transcripts, and products". Notice the identifiers for the nucleotide and protein sequences of p53 and its isoforms. (What are isoforms?) As you saw earlier, these identifiers are typical of RefSeq identifiers. There is a small graphic in this section showing "coding regions" and "untranslated regions". This shows the intron-exon structure of this gene and all its isoforms. It is small and hard to see the details of the structure clearly. We are going to navigate and study this in excruciating detail next. Also, you could click on "Try our new Sequence Viewer", you will have another graphical view of the sequence features. Instead, quickly scroll down this page and look at all the sections listed on this page. The different topics are summarized in the "Table of Contents" on the right side of the page. Before you finish this assignment, you need to understand the nature of information on this page (regardless of whether or not I have explicit questions directing you).
In the section titled "Genomic regions, transcripts, and products", clicking on "NM_000546.4" or "NP_000537.3" in the subsection titled "mRNA and Protein(s)" will take you to GenBank entries of the corresponding sequences. Study these GenBank entries. They are typical of all GenBank entries. A GenBank entry gives you sequence details, tells you where the database submission came from, and gives information about related sequences, and has citations to the scientific literature. Note that the actual sequence of nucleotides is at the bottom of the report. Locate its "GI" number. After some preliminary information about the entry, there are some references cited for this entry. This gene/protein has clearly been researched extensively. Many more references are available from PubMed and we will inspect them later. Find the section titled "COMMENT". This provides a summary of information on the p53 gene. This is followed by a section on "FEATURES". Study this carefully, especially the nucleotide sequence at the end of this page. In the CDS section, you will also find the amino acid sequence of the corresponding protein (and a link to this protein product -- NP_000537). CoDing Sequence (CDS) is the region of nucleotides that corresponds to the sequence of amino acids in the predicted protein. It includes start and stop codon, and does not correspond to the mRNA sequence. The TP53 sequence can be disaplyed in many formats. Try displaying the sequences in Fasta formats. Also try out the XML and Graph formats. Each entry in the GenBank database has several pieces of information identifying it.
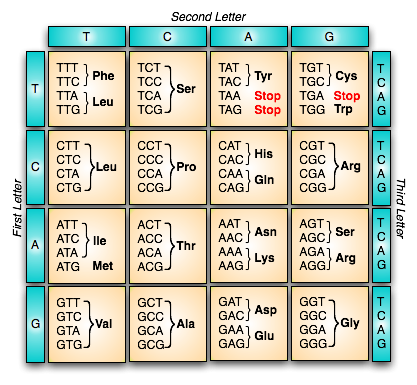
Q3: Explain the following terms in about one sentence each: LOCUS NAME, ACCESSION NUMBER, GI NUMBER, RefSeqID. How many nucleotides does the mRNA sequence for human p53 have? What is its GI number? How many residues does the protein sequence for human p53 have? What is its GI number? What were the start and stop codons in the mRNA sequence? You may use the Genetic Code, if needed.
Go back to the TP53 page, back to the subsection titled "Genomic regions, transcripts, and products". Click on the "CCDS" version of "isoform a". This will take you to the consensus CDS page for this entry. Here you would be able to find all the exons of TP53.
Q4: How many coding exons are there in this GenBank entry for the human p53 gene? What are their coordinates and lengths? How many (mRNA) exons? Write down their coordinates and lengths. Write down the amino acid sequence produced by the second coding exon. List out all amino acids encoded across a splice junction and the exon numbers that they span.
Go back to the TP53 page. On the right panel, click on "Reference Sequences". Scroll down until you see "RefSeqs of Annotated Genomes". You will find several sets of sequences. Find out more about the "Genome Reference Consortium Human Build 37 (GRCh37)", the "Celera" Assembly, and the "HuRef" assembly (do you know what they refer to?). Explore each of these entries. Click on "GenBank" link for NT_010718.15 to explore further. Note that this is the dominant transcript and is referred to as "isoform a".Go to the "display" option in the menu at the top of the page and pull down the "Graphics" option. Eukaryotic genes consist of exons and introns. These are better viewed in the graphic display under the "Graphics" format. The top part shows the region of the chromosome being considered here. The thick green lines in the lower part represent the genes in this region. The other green bands show the locations of key features in this gene. There is also a navigational icon on the left hand side to adjust the "Zoom level". Play with this to see it under different levels. The light green rectangles are the exons in the mRNA sequence made by this gene. The dark green rectangles are the coding exons. Only a part of the mRNA of this gene is translated by the ribosome into amino acid residues. Identify the portion of the first and second mRNA exons that are not translated. This corresponds the 5' untranslated region (UTR) of the mRNA. Identify the portion of the last exon that is not translated (this is part of the 3' UTR). If you navigate and zoom into the coding exons far enough, they even have the amino acid sequences shown in the browser. Mousing over can give you information about the exons.
Q5: Write down the coordinates of the untranslated 5' and 3' regions of this gene. Describe in one sentence each the following assemblies: "Genome Reference Consortium Human Build 37 (GRCh37)", "Celera", and "HuRef".
On the right side of the TP53 page, you will find a long list of Links. Click on "SNP: GeneView". SNP stands for single nucleotide polymorphisms. These are single nucleotide mutations or changes between different versions of the same gene. There is a table of all these SNPs. Read about the difference between a "synonymous" and a "non-synonymous" mutation.
Go back to the TP53 page. Go to the "Bibliography" section and click on the "PubMed" link. This will take you to the PubMed page (read about PubMed) and will give you a link to each of the over 4000 publications that report on the p53 gene or protein. Clikcing on articles will help you read the abstract of the publication. Clicking on articles that say "Free Article" will help you download or read the corresponding publication. How many are free articles and how many are review papers. All of this indicates the critical role played by p53 and the amount of research that has gone into it. Try the "Advanced Search" to see all the features available for you to search better. For example, locate a review article by "Matakidou et al." from the journal "Mutagenesis" from 2003. Feel free to browse through some of the abstracts.
The GeneRIF portion lists out functions that p53 may be involved in. Under the "Phenotypes" section, you can find out how p53 is linked to a variety of diseases. Follows the link to one of them (say, Breast Cancer) and find out how p53 may be involved in the disease. Under Pathways information, you can find various processes in which p53 is involved. Go to the "Gene Ontology" section. This annotation is provided by the Gene Ontology Consortium. Later this semester, we will learn more about GO.
We now move on to BLAST. Go to the BLAST homepage. Follow the link for Blasting 2 protein sequences (bl2seq) under "Specialized BLAST". Choose the "blastp" program. Align 2 proteins with IDs "P53_HUMAN" and "P53_XENLA". Download these sequences from GenBank.
Q6: Print out the alignment output by BLAST.
Play around with the various options that BLAST offers and see how it affects the output. Make sure you check out the Graphic Summary and the Dot Matrix View of the alignment.
Next go to the Standard Protein Blast page. Cut and paste a FASTA formatted version of p53 (gi 269849759) into the "Search" box. Confine your search to the PDB database. Study the graphic view showing the various domains in this protein and the 65 or so color coded hits. Study the pairwise alignments shown at the bottom of the results page. Follow the link for protein-protein BLAST (blastp). Study the other default parameters used by blastp. Then "Blast" it. Which ones are significant and why? Pick one of the hits and study the pairwise alignment. Read the BLAST tutoral pages and find answers to the following questions. There is no need to write down your answers. This is merely for your benefit. Find the definitions of the following terms: Score (bits), E-Value, Identities, Positives, and Gaps . Figure out how Score and E-Values are computed. Figure out how E-Value is different from P-Value of an alignment.
Now scroll down to the bottom of the results page. You will see a summary of your search. Figure out what the information down there means.
Q7 (do not submit): Repeat questions 2 through 4 for the human protein "insulin". Also study some of the interesting SNPs. This is just an exercise and is not for submission.
Q8: Run the Needleman-Wunsch global sequence alignment algorithm on the sequences "VEPPLSQETFSDLWKLLPENNVLSPL" and "MDPPLSQETFEDLWSLLPDPL" using the BLOSUM62 substitution matrix, gap open and gap extension penalties of 11 and 1 respectivey. Write down the optimal alignment and the alignment score.
{kind=link}