CDA-4101 Lecture 3 Notes
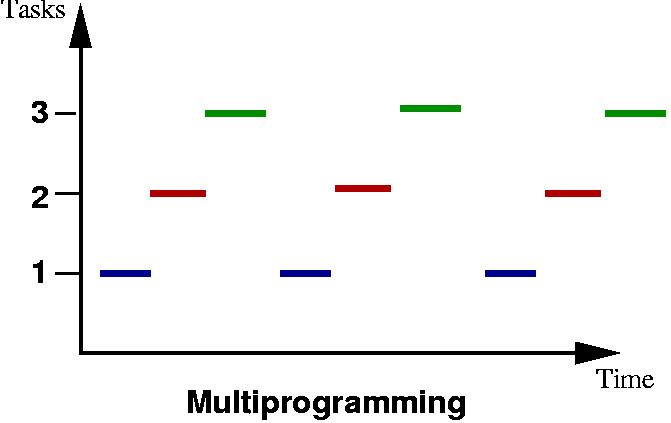
Processors: Parallelism
- There are limits to how fast you can get the full
fetch-decode-execute cycle to run.
- Doing multiple things at the same time (parallelism) is an
alternative to increasing the execution speed.
Instruction Level Parallelism - multiple instructions executing on the
same CPU
- pipelining
- superscalar architectures
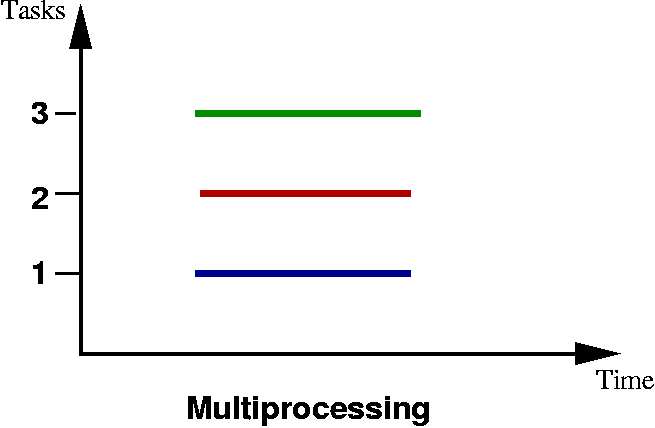
Processor Level Parallelism - using multiple CPUs to execute instructions
- array processors
- vector processors
- multiprocessors
- multicomputers
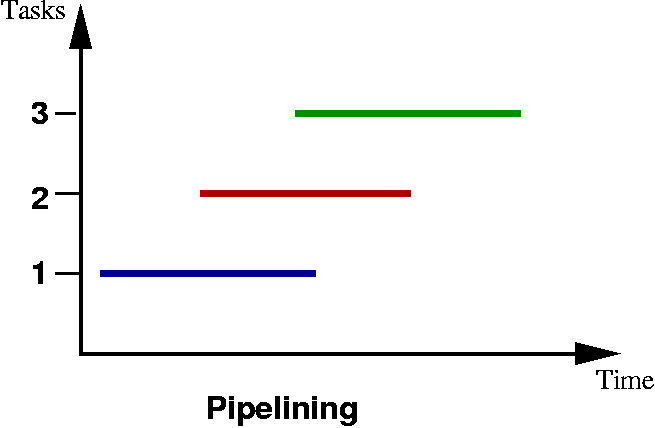
Pipelining

Pipelining?
| 
Monte-Carlo Assembly Line
| 
Henry Ford meets CPUs
|
Early Pipelining: Prefetch Buffers
Before Prefetch Buffers
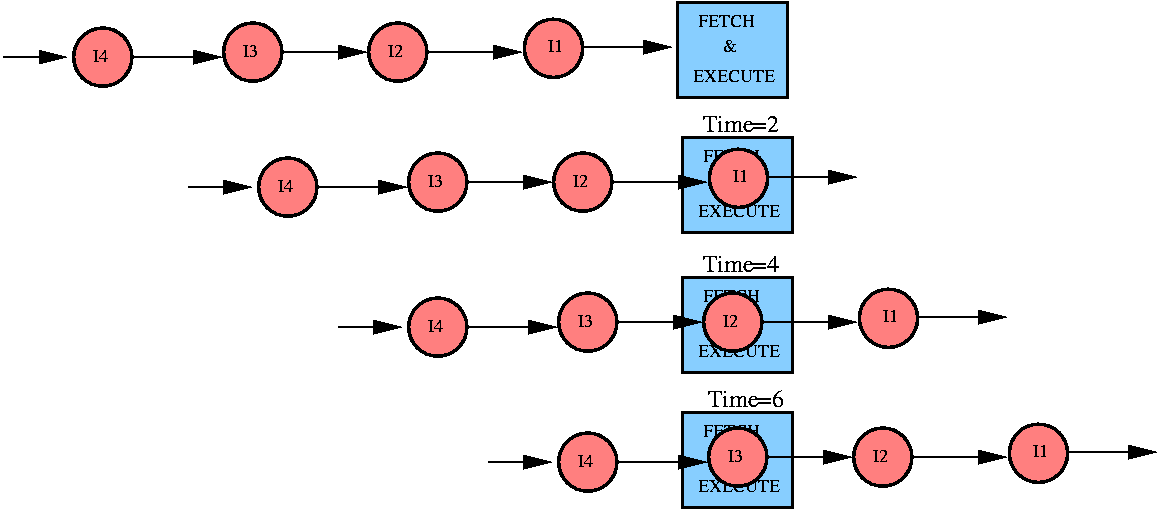
IF = Instruction fetch, EX = Instruction execute,
In = Instruction n
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6
|
|---|
| I1 | IF | EX | | | |
|
|---|
| I2 | | | IF | EX | |
|
|---|
| I3 | | | | | IF | EX
|
|---|
After Prefetch Buffers
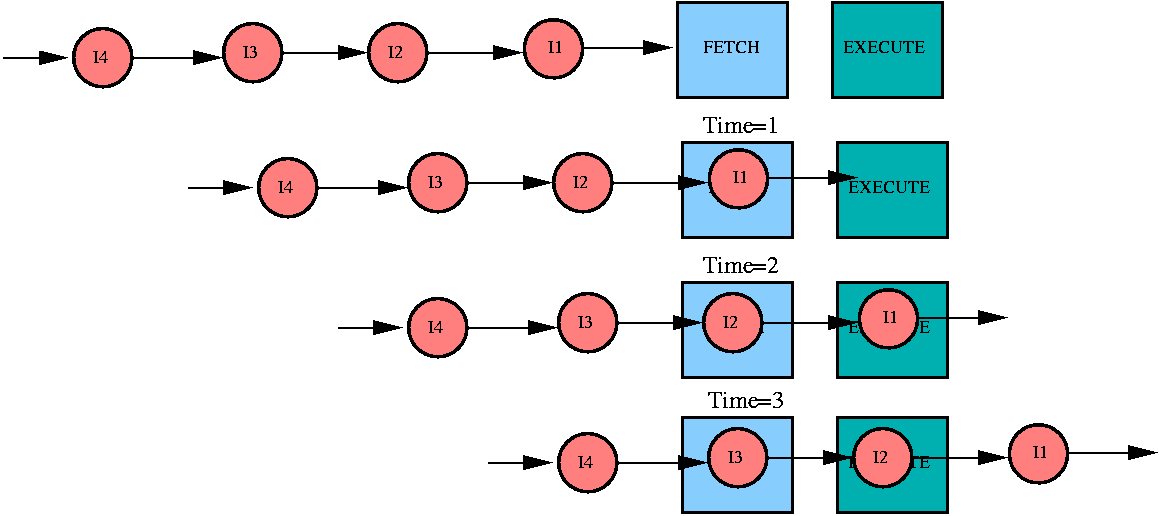
IF = Instruction fetch, EX = Instruction execute,
In = Instruction n
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6
|
|---|
| I1 | IF | EX | | |
|
|---|
| I2 | | IF | EX | | |
|
|---|
| I3 | | | IF | EX | |
|
|---|
| I4 | | | | IF | EX |
|
|---|
| I5 | | | | | IF | EX
|
|---|
Five Stage Pipeline

| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6
| t7 | t8 | t9 | t10 | t11
|
|---|
| I1
| IF | ID | OF | EX | WB
| | | | | |
|
|---|
| I2
|
| IF | ID | OF | EX | WB
| | | | |
|
|---|
| I3
| |
| IF | ID | OF | EX | WB
| | | |
|
|---|
| I4
| | |
| IF | ID | OF | EX | WB
| | |
|
|---|
| I5
| | | |
| IF | ID | OF | EX | WB
| |
|
|---|
| I6
| | | | |
| IF | ID | OF | EX | WB
|
|
|---|
| I7
| | | | | |
| IF | ID | OF | EX | WB
|
|---|
- Instruction latency is 5 cycles
- Ability to "issue" an instruction every cycle
- After time 't4', an instruction finished every single cycle
- Processor bandwidth is one instruction per cycle
Pipeline Math
Example
- Assume each stage takes 20 nanoseconds.
- Without pipelining:
- instruction latency is 100 ns
- execute 10 instructions per microsecond, or 10 MIPS
- With pipelining:
- cycle time is 20 nanosecods
- execute 50 instructions per microsecond, or 50 MIPS.
|
Definitions:
- nanosecond (ns) - one billionth of a second (1 x
10-9 secs.)
- microsecond (μs) - one millionth of a second (1 x
10-6 secs.)
- millisecond (ms) - one thousanth of a second (1 x
10-3 secs.)
- MIPS - millions of instructions per second.
|
|
Pipelining Realities
There is an apparent factor of 5 speed-up in a 5 stage pipeline.
Problems:
- All stages must execute in the same amount of time, so "cycle"
time has to be as long as the stage that takes the maximal
amount of time.
- Care must be put into decomposing the design into stages.
- Taking a 100 ns hardware operation and dividing into 5 parts
that execute in exactly the same time is difficult.
- Idealistic calculations assume pipeline to always be "full".
- Hazards!
Pipeline Hazard Types
Examples to follow.
- Data Hazards - when an instruction needs data that is not
yet available.
- Structural Hazards - when the same hardware is needed by
more than one instruction in the pipeline.
- Control Hazards (Branch Hazards) - when changes to
the program counter affect the pipeline execution.
| 
|
Structural Hazards
- Suppose the IF (instruction fetch) stage and the OF (operand fetch)
stages both need to access main memory for their data.
- Suppose we only have one data path to main memory.
- We will not be able to execute an IF and an OF at the same time.
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | OF | EX | WB
| |
|
|---|
| I3
| |
| IF | ID | OF | EX | WB
|
|
|---|
Structural Hazard Remedy: Duplicate Hardware
- One solution is to add redundant hardware to avoid these
hazards.
- Decision depends on the design costs, transitor constraints and
the performance increase it will yield.
Structural Hazard Remedy: Stalling
- Another solution is to stall the pipeline, but this will
reduce the overall processor performance.
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | OF | EX | WB
| |
|
|---|
| I3
| |
| -- | IF | ID | OF | EX | WB
|
|---|
- In this case, stalling for one stage results in another conflict so we
must stall for two stages.
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | OF | EX | WB
| |
|
|---|
| I3
| |
| -- | -- | IF | ID | OF | EX
|
|---|
- Obviously a prefetch buffer would be useful here.
Data Hazards
Consider the following 2-instruction code using our 5 stage pipeline:
I1: R3 := R1 + R2
I2: R4 := R3 + 10
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | OF | EX | WB
| |
|
|---|
- Instruction I2 needs the data from R3 at time 't4' (operand fetch).
- However, I1 hasn't finished yet, so R3 value has not been written
back and will not be available until after time 't5'.
Data Hazard Remedy: Stalling
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | -- | -- | OF | EX | WB
|
|---|
Data Hazard Remedy: Data Forwarding
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | -- | OF | EX | WB
|
|
|---|
- requires extra hardware/more complex hardware design
Data Hazard Remedy: Instruction Reordering
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I3
|
| IF | ID | OF | EX | WB
| |
|
|---|
| I4
| |
| IF | ID | OF | EX | WB
|
|
|---|
| I2
|
| | | IF | ID | OF | EX | WB
|
|---|
- Who reorders the instructions: hardware or compiler?
- Reordering instructions and preserving proper program semantics
can be tricky
- Reordering instructions can cause its own conflicts
Types of Data Hazards
- Previous was an example of a read-after-write (RAW) data hazard
- There are also write-after-write (WAW) and write-after-read
(WAR) data hazards that occur, especially when instructions are
reordered.
Control Hazards
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | OF | EX | WB
| |
|
|---|
| I3 | I4
| |
| IF | ID | OF | EX | WB
|
|---|
Control Hazard Remedies: Instruction Reordering
- Stalling after each branch
| | Time
|
|---|
| | t1 | t2 | t3 | t4 | t5 | t6 | t7 | t8
|
|---|
| I1
| IF | ID | OF | EX | WB
| | |
|
|---|
| I2
|
| IF | ID | OF | EX | WB
| |
|
|---|
| I3 | I4
| |
| -- | -- | --
| IF | ID | OF
|
|---|
- Discarding pipeline results.
- Guessing which branch will be taken (branch
prediction)
Real Pipelining
Pentium I:
- 5 stage pipeline (instructions)
- 9 stage pipeline (floating point)
| Pentium III:
- 10 stage pipeline
- Two ALUs and can operate at 1/2 clock cycle
|
Pentium IV:
- Transistor Count: 55 million
- 20 stage pipeline
| UltraSparc III:
- Transistor Count: 29 million
- 14 stage pipeline
|
Superscalar Architectures
- Duplicating pipeline stage hardware can prevent stalls and get more
instructions executed,
- The extreme case, which is now commonly used, it to duplicate the
entire pipeling to get more instructions executing in parallel.
- Procesors with multiple pipelines are termed superscalar
(this also is instruction level parallelism)
Pentium
- Even the Pentium I had two pipelines.
| UltraSparc III
- Six execution pipelines (2 integer, 2 FP/VIS, 1
load/store, 1 addressing)
|
Superscalar Configuratons
- There are many ways to organize parallel pipelines.
- Common prefetch stage:
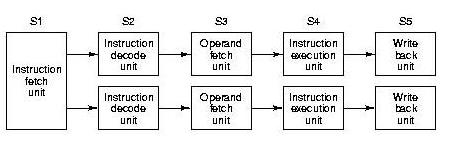
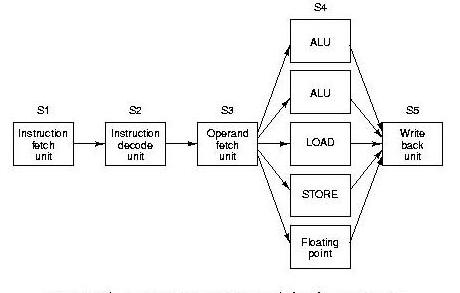
- Multiple functional units, (e.g., one stage takes longer than
the others)
Processor Level Parallelism
- There are limits to what can be achieved with instruction level
parallelism
- greater speed-up factors are possible by using multiple
processors
- At some level, a pipelined processor could be viewed as
consisting of multiple processors where each processor is
specialized and sequenced.
Flynn's Taxonomy* of Parallel Processors
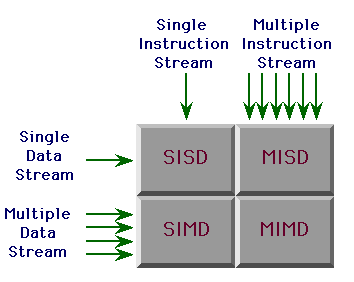
*Flynn, M. J., Some Computer Organisations and their Effectiveness.,
IEEE Transactions on Computers, C-21 (9), pp 114-118, Sept 1972.
Images of parallel machines borrowed from:
http://www.cems.uwe.ac.uk/teaching/notes/PARALLEL/ARCHITEC
SISD (no parallelism)
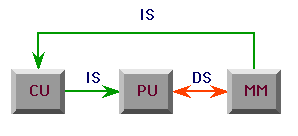
- von Neumann architecture is SISD
- with pipeling and superscalar architectures, modern processor do
not fit so neatly into this classification
SIMD
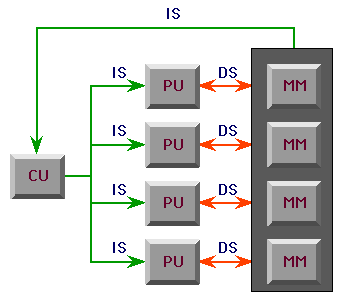

Illiac IV
|
- array processors - same instruction executes all all processor,
only data varies
- vector processor - similar to array processor, only a single
instruction executes by passing many data words through a
heavily pipelined ALU
| 
Cray 1
| 
Cray SV1
|
MIMD
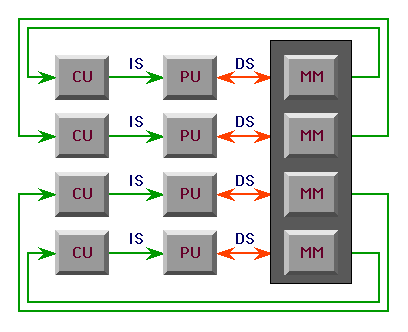

Motherboard
(2 processors, shared-memory)
| MIMD can use either:
- shared memory (a.k.a., multi-processor machine)
- communicate through shared memory
- distributed memory (a.k.a., multi-computer
machine) - commuicate through message passing
| 
Cray Y-MP
(8 processors, shared-memory)
|
Multiprocessor Arrangements
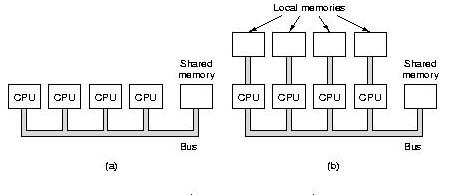
(a) True shared memory
(b) Hybrid shared/distributed memory
Multicomputers
- Rely on message passing for communication and coordination
- Too many connections is costly and unmanageable
- Which processors can talk to which other processors?
Distributed Memory MIMD
| |
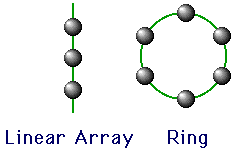
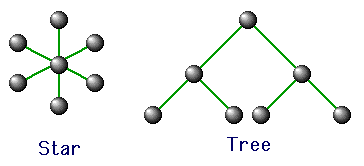
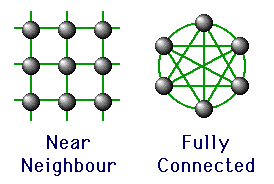
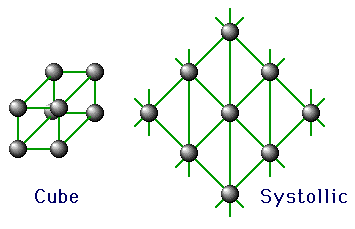
Message Passing Topologies
MISD?
- No machines really fit this description
- At best, you have to be creative to fit any current machines into this
classification.
Flavors of Parallelism
Final Observation
- A typical PC is sort of a fully connected multi-computer
- Multiple processors:
- CPU
- video card
- bus controllers
- disk controllers
- etc.
- Control signals are the messages
- Common communication bus gives full connectivity
| 
|