This chapter covers results in the paper Fast Axiomatic Attribution for Neural Networks available at this Arxiv link.
The lecture slides are available here.
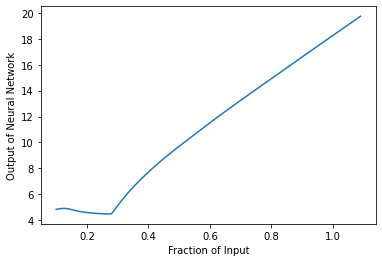
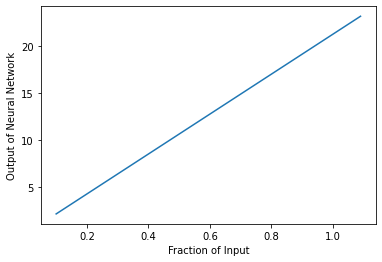
A minimal working example for creating a simple X-DNN for MNIST is presented in the Colab document. The same code without the modification essential for making the network nonnegatively homogeneous is presented in this Colab document. The plots below compare how the output of the two models change on the Y-axis as the input is scaled from 10% to 100%. The X-DNN has a linear plot while the ordinary DNN does not show a linear behavior.
| DNN | X-DNN |
|---|---|
|
|
Using any input benchmark of your choice, such as FashionMNIST or CIFAR-10, write a Jupyter notebook to implement an X-DNN or a nonnegatively homogeneous deep neural network of your choice (40 points). Do not copy code from the minimal working example above.
Using your X-DNN implementation, implement an integrated gradient attribution using the approach shown in the paper that involves a single forward/backward pass. Demonstrate your approach on 10 different input examples. (40 points)
Using your X-DNN implementation, implement the saliency map attribution approach covered in the course earlier and qualitatively compare the results with the IG approach implemented in (1) above. Show your results on 10 different input examples. (20 points)
Suggest an approach for learning X-DNNs based on ResNet-18 and ResNet-50 models. Implement and evaluate your approach on at least 10 examples from the ImageNet or a similarly complex high-dimensional data set. (optional extra credit: 100 points)
These assignments will be evaluated as graduate assignments, and there is no single correct answer that is expected. A variety of answers can equally satisfy the requirements in the above assignments.
Q1. Do we have to use the MNIST benchmark?
A1. You can use ImageNet, CIFAR-10, or any benchmark data set of your choice. You can even use a data set of another modality, such as text, speech, EM signals, etc.